Hệ
thống tìm kiếm thông tin của tập đoàn công nghệ Google được hàng trăm
triệu người sử dụng mỗi ngày. Theo một thống kê gần đây, Google chiếm
khoảng 78% thị phần tìm kiếm trên toàn cầu, bỏ xa thị phần của các công
ty nổi tiếng khác như Baidu, Yahoo, hay Microsoft. Cứ mỗi giây, cỗ máy
tìm kiếm của Google xử lí khoảng 40,000 truy vấn; tức xử lí khoảng 3.5
tỉ truy vấn mỗi ngày, và các con số này tăng dần mỗi năm.
Với
mỗi truy vấn mà người dùng nhập vào, cỗ máy tìm kiếm của Google cần tìm
mọi trang web liên quan tới truy vấn và xếp hạng chúng theo một thứ tự
ưu tiên để hiển thị kết quả cho người dùng. Số website trên toàn cầu là
rất lớn, ước tính hiện tại có khoảng gần 2 tỉ website¹. Mỗi website
thường chứa nhiều trang web (webpage). Ước tính số lượng trang web là
rất lớn, hàng chục tỉ trang. Trong bài viết này, chúng ta sẽ tìm hiểu sơ
bộ phương pháp Google sử dụng để xếp hạng các trang web này. Có thể tóm
gọn về bản chất, mỗi khi ai đó tìm kiếm, Google sẽ cần giải một hệ phương trình tuyến tính rất lớn. Ở đây, vai trò của các kiến thức toán học là không thể thiếu.
Trước
tiên, ta thấy rằng các trang web quan trọng thì cần được xếp hạng cao
hơn các trang web ít quan trọng. Điểm mấu chốt ở đây là ta cần lượng hoá
được độ quan trọng của mỗi trang web. Về mặt trực quan, ta
thấy rằng nếu có nhiều trang web quan trọng cùng liên kết tới một trang
web A nào đó thì A rất nhiều khả năng là trang web quan trọng. Chú ý
rằng các liên kết này là có chiều: trang web A liên kết tới trang web B
nhưng B không nhất thiết liên kết tới A.
Về
mặt hình ảnh, các trang web lập thành một đồ thị, hay một mạng gồm các
cung có hướng. Mỗi đỉnh của đồ thị là một trang web, đỉnh A có cung đi
tới đỉnh B nếu trang web A chứa liên kết tới trang web B. Đồ thị này là
một đồ thị rất thưa, theo nghĩa số đỉnh thì rất nhiều (hàng chục tỉ),
trong khi số cung thì rất ít nếu so với số đỉnh – thông thường mỗi đỉnh
chỉ nối với một số ít số đỉnh khác.
Giả sử có N trang web, mỗi trang web i có Oi liên kết đi ra khỏi nó và có Ii liên kết tới nó. Ta kí hiệu πi là độ quan trọng của trang web i. Theo giả định “ngưu tầm ngưu, mã tầm mã” ở trên, ta thấy rằng nếu có một số trang web quan trọng liên kết tới trang A thì trang A sẽ là trang web quan trọng, tức là ta có thể xấp xỉ πA = ∑i→Aπi, trong đó tổng tính theo mọi trang web liên kết tới A. Tuy nhiên, xấp xỉ này không tốt bởi trang web i
có thể liên kết tới rất nhiều trang web khác trong mạng, do vậy, mỗi
trang đó sẽ chỉ được chia một phần nhỏ của độ quan trọng của trang web i.
Giả
sử độ quan trọng của mỗi trang web (hay mỗi đỉnh trong đồ thị) được
phân phối đều cho các liên kết đi ra khỏi trang web đó. Nói cách khác,
mỗi đỉnh ra kề với đỉnh i sẽ nhận được độ quan trọng πi/Oi từ đỉnh i.
Như vậy, ta có thể xấp xỉ độ quan trọng của mỗi đỉnh bằng cách lấy tổng
tất cả các độ quan trọng mà nó nhận được từ các đỉnh kề đi vào nó, ví
dụ với đỉnh 1:
π^1 = ∑j→1πjOj
Nếu π^1 ≡ π1
thì ta có điểm số quan trọng phù hợp, hay vững. Về mặt toán học, chỉ
với một số thay đổi dựa trên ý tưởng ở trên, ta có thể tìm được một bộ
điểm số vững và duy nhất cho mọi đỉnh của đồ thị, kí hiệu là {π∗i}
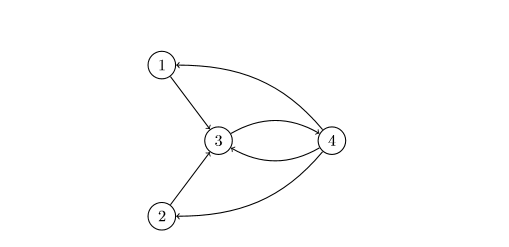 Hình 1: Một đồ thị trang web đơn giản.
Hình 1: Một đồ thị trang web đơn giản.
Xét một đồ thị ví dụ nhỏ như trên Hình 1 với 4 trang web và 6 liên kết². Bộ điểm số quan trọng của đồ thị này là π = [0.125,0.125,0.375,0.375]. Đồ thị này có ít đỉnh và đối xứng để dễ tính các điểm số. Cách tính π
như sau. Ta thấy đỉnh 1 và 2 tương tự nhau vì đối xứng, mỗi đỉnh có một
cung ra và một cung vào. Giả sử độ quan trọng của chúng đều là x.
Nếu gộp hai đỉnh 3 và 4 lại thành một “siêu” đỉnh 3+4 thì siêu đỉnh này
có 2 cung đi vào, do đó sẽ quan trọng hơn các đỉnh 1 và 2. Bên cạnh đó,
đỉnh 3 trỏ tới đỉnh 4 và ngược lại, đỉnh 4 trỏ tới đỉnh 3 nên hai đỉnh
này chia sẻ độ quan trọng với nhau theo cách cân bằng. Giả sử độ quan
trọng của các đỉnh 3 và 4 đều là y. Xét đỉnh 1, ta thấy nó chỉ có một cung đi vào xuất phát từ đỉnh 4; trong khi đó đỉnh 4 có ba cung đi ra, nên x = y/3. Theo điều kiện chuẩn hoá, tổng các điểm số là 1 nên ta có 2x + 2y = 1. Giải hệ hai phương trình:
3x − y = 0
2x + 2y = 1
ta thu được x = 0.125 và y = 0.375.
Trong
thực tế, Google nói riêng và các bộ máy tìm kiếm khác nói chung cần
giải một hệ phương trình tuyến tính rất lớn, tương ứng với ma trận đại
số G cỡ N × N, với N là số trang web liên quan tới truy vấn tìm kiếm. Giả sử π là véc-tơ cột kích thước N × 1 và πT là chuyển vị của nó. Ban đầu, ở thời điểm 0, ta có thể khởi tạo π = π0 là một véc-tơ ngẫu nhiên và liên tục cập nhật nó bằng thủ tục lặp
πTk+1 = πTkG,
trong đó πk là véc-tơ điểm số ở bước thứ k. Nếu G có một số tính chất toán học phù hợp thì véc-tơ πk sẽ hội tụ tới một véc-tơ duy nhất π∗ khi số bước k đủ lớn:
π∗T = π∗TG
Nói cách khác, π∗ là véc-tơ riêng trái của G ứng với giá trị riêng bằng 1.
Tóm
lại, mỗi khi có người tìm kiếm, Google cần tính toán độ liên quan và độ
quan trọng của các trang web chứa kết quả. Để thực hiện tính toán này,
ngoài các yêu cầu về công nghệ trong việc tổ chức, lưu trữ dữ liệu rất
lớn, Google cần giải một số bài toán lõi vốn trực tiếp cần tới các kiến
thức về đại số tuyến tính, giải tích số, xác suất thống kê và khoa học
máy tính. Hơn thế nữa, các thuật toán đó cần phải thực hiện rất nhanh để
đáp ứng nhiều tỉ truy vấn tìm kiếm mỗi ngày.
Chú thích:
¹Theo http://www.internetlivestats.com/
²Ví dụ này được trích từ cuốn sách Networked Life của GS. Mung Chiang.